This post is part of a series focused on exploring DVS 2020 survey data to understand more about tool usage in data vis. See other posts in the series using the ToolsVis tag.
In the last installment, I focused on extracting simple counts from the tools dataset to get an idea of what was in there, and to explore some of the basic questions that we can answer with this data. In my opinion, the more interesting set of questions revolve around connections in usage between tools, so next I wanted to start investigating those. There are a variety of ways to get at the connections between tools, but my first approach was to export a full tree of unique paths through the data using one really long groupby command in R.

Even a preliminary glance at a very zoomed out version of the Excel sheet confirmed two things. First, this was the core data structure that I wanted: I could see all of the different tool lineages within the dataset. The second thing it confirmed was that mapping out the whole tree was more likely to create a hairball than a useful vis.
This is also a good reminder that sometimes you don’t need a fancy tool to get insight into your data: the image above is just 3 screenshots pasted together from one very long table in Excel, and then rotated to fit better on the page. Because there’s enough structure in the data, it’s able to stand as a rough form of visualization all on its own.
Unfortunately, the table itself isn’t particularly readable as-is, so I did a little bit of secondary analysis to be sure I knew what was going on. A few simple sum checks in Excel confirmed that I was getting the results I expected from the groupby command (always useful to check, when using new software that makes complicated analysis seem easy). I also noticed that this operation also doesn’t reduce my data size by much: I went from 1766 to 978 rows in the data. I did a quick summary vis to look at the distribution of “branches” by sorting the tool tree based on the count of users and putting the raw results into a column chart.


The first thing I notice here is that the counts fall off very rapidly, and there is an extremely long tail of unique branches. Zooming in a little bit on the first 50 results, I can see that there is one bar with a value of 401 responses, and the rest are much, much smaller. Closer inspection reveals that the 400 bar represents a group of respondents with nothing selected except “other.” There are no blanks in the “other” column for this dataset, so it seems that the survey tool returns a positive response for anything except the case where a person specifies a different tool. That seems odd to me, but it appears to be the case. What that means for my analysis is that the largest group of tool users are people who either selected only the “other” option or who didn’t respond! This is why it’s always good to take a closer look at what’s really in the data before getting too excited about a summary statistic. I specifically chose to keep the non-responses in this dataset for now because I want to be able to compare my results for this question with other analyses that I’m running elsewhere, but it’s always good to remember the impacts that “little” decisions like that can have on the results that you see, and never to analyze blindly.

If I remove the “other” row from the chart data, I get a better look at the shape of the tail for the real responses. The dropoff is still pretty sharp, dropping off to 2 responses per branch by the 50th bar, and 1 response per branch after 101 bars. What that means is that most tool combinations in the dataset are unique, though there are a few combinations that are shared. It also means that most of my data points will be vanishingly small if I try to do any kind of visualization that scales by size.
One more place that the “other” category complicates things is in the free response piece when a user chose to specify a piece of software. Each of those free-text entries is likely to be unique, and won’t get bucketed in with other branches, even if all of the other tools are the same. This makes my list of unique rows longer, and increases the length of the tail in my chart. Filtering on the column told me that there are only 283 specified “other” responses in the dataset, so that could account for up to a third of my unique branches. Visual inspection showed that there were several cases where the “other” category was the only item that made a branch unique, but there are also some cases where it wasn’t the deciding factor. That’s not a major impact for now, but it’s something that I’ll need to keep in mind on the final cleanup. I’ll probably exclude the “other” category from the groupby command in the actual analysis, or I could manually merge those responses in a more thoughtful way.
Once I understood what was in the tree, the next step was to decide whether this analysis gets me any closer to my goal of understanding which tools are most often grouped together. After a couple of days of playing around with filter and sort operations and secondary analyses, I decided that this specific analysis isn’t getting me closer to where I want to be for right now, and in some ways it’s complicating my pivot table analysis for other things. It’s very easy to use Excel pivots to count entries on a flat dataset, where there is one row per entry. Once you create the tree and aggregate into branches, there is one row per group of entries, and a new column with a branch count value for that row. It’s still possible to use pivot tables with data in this format by switching from a simple count of rows to a sum of the branch count column, but I found that it was getting in the way of my other analyses more often than it was helping, so I went back to using the raw data instead.
The fact that I spent several days on this analysis doesn’t discourage me at all; I’m putting it down for right now, but I suspect that it may be useful to come back to it later, and I learned some important things about the “other” responses along the way. Rabbit holes and dead ends are just part of the process in the expand phase, and I’d prefer to have explored this and discarded it quickly than to have spent a long time building up to something that doesn’t work the way I want.
In the end, the most useful visualization that I got from this exploration was the zoomed-out view of the tree data in my raw Excel sheet. That gives me a really good idea of the branching patterns and the degree of ramification within my dataset. If I want to draw a Sankey later, this is the number of connections I’ll have to deal with. If I look at a treemap, I should expect it to be very finely divided. It’s also important to realize that sequence matters: this tree will branch differently depending on the order in which I group by the tools. Some of the major tools have much larger branches, so moving them to the beginning of the analysis could help to reduce early divisions and keep the analysis more manageable. If I were to go back in this direction for my final visual form, I would consider sorting the analysis by the most popular tools, or the ones that have the largest branch sets, rather than using the arbitrary order given in the original data.
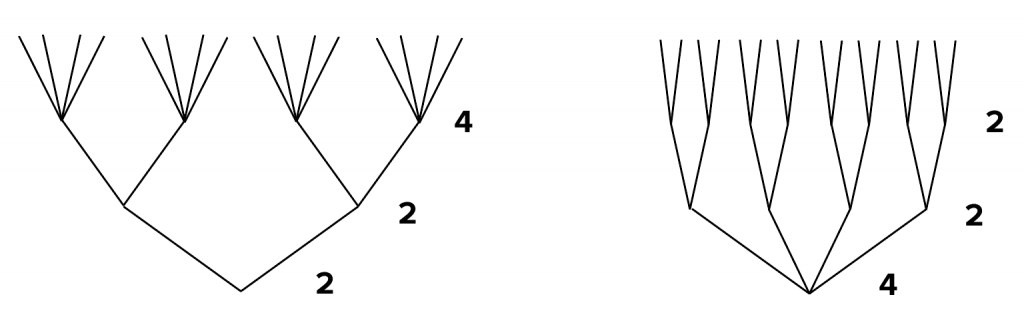
You can’t reorder the branch points like this if the data itself contains a sequence: if this were a diagram of survey completion, I would never put question 10 as the second branch point, no matter how much it simplified the chart. In the tools case, the sequence is arbitrary: there’s no reason that Excel or ArcGIS or d3 should come first. We might be able to add a sequence that is meaningful (sort by the most popular tool), but there’s nothing to stop us from optimizing to make a more compact or readable shape. There’s a judgment call to make about what visual form best matches the data, as well. A dendritic (tree) structure will give the impression of sequence, even if the sequence doesn’t exist. If I impose a sequence on the data, I should be aware that there’s a narrative element to that as well: questions that come first are usually the most important branches in a decision tree. That’s not necessarily bad, but it’s worth asking whether you want to introduce an arbitrary value into your encoding, alongside meaningful data values.