I’ve taken an unexpected pivot in the past couple of months, and took on a position as director of education for the Data Vis Society. As a result of that, some work craziness, and needing to move unexpectedly this summer, the PlantVis project is on hold until further notice. But there’s still a lot of data vis going on around here.
One of the first projects that I started working on for the DVS was getting basic information about our membership out of the survey data that the project collects every year. That’s been giving me a chance to develop some of my fledgling R skills, and also to do some data vis. The next step is to deepen this analysis, and start building out portraits of what different career paths look like in the field.
Information about which tools people use is one of the most interesting data sets in the survey, in my opinion. I’m in the early “expand/ideate” stages of a project to explore that one question, just trying to understand what’s in there and to draft out some ideas. What that looks like right now is a tiny bit of analysis in R to export a spreadsheet, and then a whole lot of manual playing around in Excel to figure out how I want the bits to work together. I’d do that in R if I had the skills, but right now I’m in the “expand” phase of the project, and I don’t want learning a new piece of software to slow me down. So I wave my magic wand in R when I can, and when I can’t, it’s good old elbow grease in Excel to fill in the gaps.
This stage of the game is about spending as little time as possible getting oriented and exploring some initial ideas. I’m looking to understand the data, what might be interesting to analyze more closely, and what kinds of questions I can coax out of the information to support an interesting narrative. I’m looking to open up and explore as many aspects of the data as I can, to identify which ones might be promising enough to come back to later, and which are likely to be dead ends. I’m also looking to assemble a strategic view of where I’m going, so that I know where to spend my time in the much slower, higher-effort “focus/consolidate” step that comes next.
I’m using Illustrator for the charts because I’m already familiar with it, I want the flexibility to sketch and ideate on top of basic data points and visual forms, and the actual data values aren’t all that important to me right now. The data points will all need to be carefully recalculated and analyzed for the final version anyway, so everything in this file is subject to change, and should be thrown out. Knowing that gives me the freedom to ignore little things like axis labels, and just dump in screenshots and notes to help myself re-connect the dots later, instead.
You may be thinking that this is a sloppy, imprecise way to work, and you would be right! To me, that’s actually sort of the point here. I don’t want to get in too deep and start taking myself seriously before I know what I’m after and where I’m going. In my experience, an analysis that looks like it might be finished is a lot more dangerous than one that is clearly a mess, because it’s easy to forget that one little thing you needed to do when you came back. I used to tell my students that the best way to avoid plagiarizing was to never copy and paste someone else’s sentence into your document. Once it’s in there, it’s really easy to forget that you need to go back and make a change, but a big block of [add something interesting here later] with a link to your references file is something you’re not likely to miss in the editing phase.
I find that the same thing applies to charts. If I make a chart that looks “real” in Excel and I skip a step in the data analysis for the sake of time, I’m much more likely to end up with an error in my final dataset. I consciously prevent that by increasing the separation between the ideation and editing stage (different tools, different files, etc.). This helps me to avoid getting bogged down in the details too early, short-circuits perfectionism, and gives me the room to move freely while I work through the strategy for a project. I also need to leave myself a trail to make sure that I can come back in and re-create the steps, which helps me to make first-draft documentation for the analysis and the project. If I know that I’m going to have to go back and figure out those cryptic notes later, it gives me a really strong incentive not to cut corners on writing things down. Writing blog posts is also a really good way to document what you’re doing at a high level, to help make sense of the details in the actual implementation notes doc.
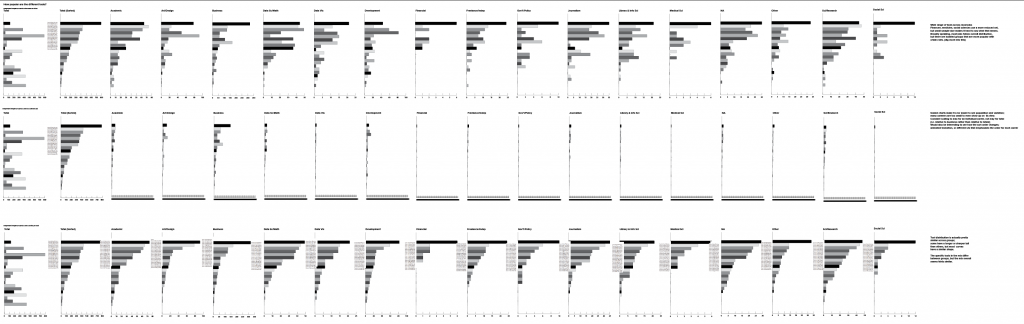
That set of charts above is just simple frequency calculations for the different tools, plugged into the most-basic, default chart possible, to help me see the data values. The first column shows the total for all career paths, and the subsequent charts show distributions for each of the subgroups. The first set of charts scales automatically to the max for each dataset; the second compares all of the subgroups against an absolute scale to see how much each career group contributes to the total. The data for the first two sets of bar charts is also sorted according to the totals column, which means that I can immediately see which tools are used the most.
The third row of bar charts shows the scaled charts for each subgroup, sorted according to their own frequency. Tool distribution is actually pretty similar across groups; some have a longer or sharper tail than others, but most curves have a similar shape. The popularity of specific tools in the mix differ between groups, but the mix overall seems fairly similar. It’s also worth noting that the n values for these charts are extremely different – that point is much more obvious in the second row, where they are all scaled to the same axis. Comparing with the absolute scaling in the previous row really helps me to know when I should be careful about drawing conclusions from the data. I often use this sort of small multiples approach to help keep me honest when looking for interesting differences, patterns, and trends in aggregated data.
These frequency bar charts helped me to answer a few first analysis questions:
- How popular are the different tools? Some tools are quite popular, and are identified as important by almost half of survey respondents. Others have only a handful of users.
- How different is the distribution of usage from one tool to another? (e.g. do people really use Excel more than other tools? The answer is yes.) Usage varies widely across the different tool groups, so this is something that may have interesting details to explore later.
- How different is the distribution between career groups? Somewhat different, but the difference is usually in frequency/count rather than presence in group, so this is a more subtle analysis that I’ll need to come back to later. Small n values also complicate the analysis, suggesting that I should possibly exclude or merge certain categories, or look for another way to improve the data (merging in data from previous years, etc.).
Unfortunately, the frequency charts can only tell you so much. They answer the question of how many people use each tool, but they don’t get into the more interesting details about which tools are used together. It’s also worth noting that the total number of answers in the bars adds up to significantly more data points than people who took the survey, because this question allows one person to select multiple tools. Many of the more interesting questions get into correlating the tools used per user, but that’s a more complicated analysis that I’ll need to build up to over time. First, I want to get a sense of what the independent counts can tell me.
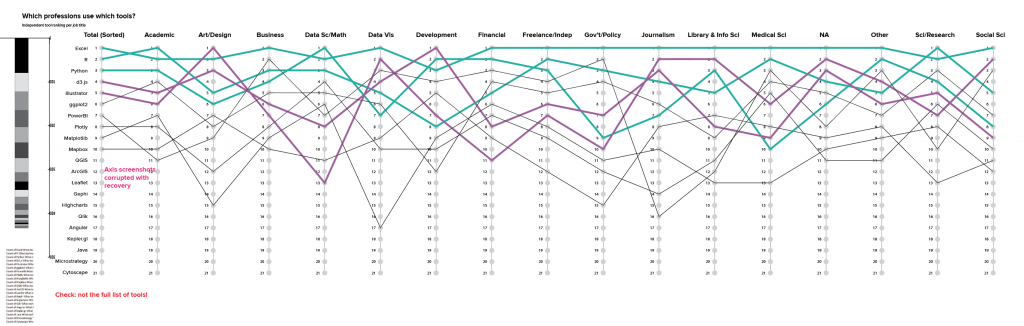
At this stage, I might also start playing around with the visual form a bit, just to capture ideas as they come up. The third row of bar charts above shows the frequency sorted by profession, but it’s hard to trace what that means for the popularity of each tool across the different groups. A multiple y plot with tools ranked based on the totals column allows you to trace a particular tool across the whole dataset. The top 3 tools are Excel, R, and Python, and all three are in the top ten most-common tools for each profession. Excel is #1 or #2 almost across the board, with an exception as #3 for developers. Python is much more variable; it is near the top of the list for several professions, but much lower for others. D3 and Illustrator show similar variability, with high usage in some professions and much less in others.
The multiple y plot gets crowded really quickly, and I didn’t want to draw out all those different connections by hand, so I contented myself with drawing lines for the top 10, and will come back and put in the effort to build this out in code later. After building the simple y plot, I also realized that it might be interesting to pull in information about the relative size of the different tools in that totals row; in addition to their order in the ranking, I’d like to see how much bigger Excel is than Java. A quick and dirty way to do that is to add a stacked bar chart at the beginning. Definitely not finished and not pretty, but it’s enough to remind me to think through that when I come back to refine this later.
This image also shows some of the pitfalls of this kind of analysis: I was using screenshots to label my axes, but my computer crashed at one point and Illustrator lost the screenshots. Fortunately, they’re just duplicates of the ones in the third row of bar charts, so it wasn’t an unrecoverable loss, but I now have some cleanup to do when I come back around to this chart. I also realized much later down the road that I had missed including some tools from the survey data in the list here. I’m not quite sure what happened there, but I think it likely has to do with dragging fields into pivot tables by hand in Excel. Good thing I needed to re-do this analysis anyway! Right now, this is just a sketch, so it’s enough for me to take a note in my documentation, and also to add a big red label right on top of the sketch.
Next, I wanted to know more about how many tools each person tends to use. This is just an interesting question its own, but it will also help me to better understand how much duplicate counting I’m likely to be doing in the previous charts. Again: one respondent can identify multiple tools in this question, so if I sum up my bars I get just north of 4000 data points, when there are only 1766 individual responses to the survey, and some of those are incomplete.
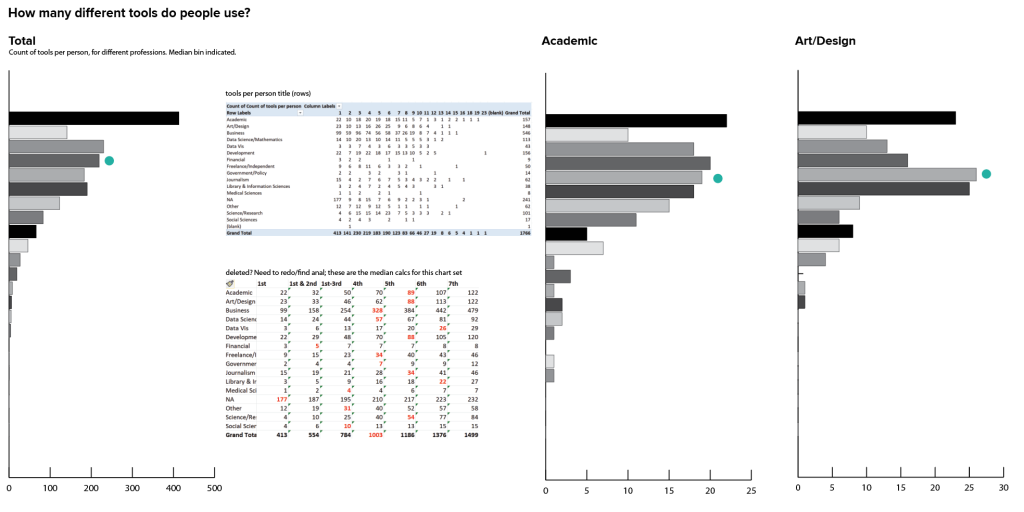

Fortunately, because of the way the data is structured, this just requires adding a countA column (to tell whether or not a cell is blank) and doing another pivot table off of the same dataset. As expected, these curves are pretty asymmetrical: lots of people use just a few tools, and then some professions have a long tail of people who use just about everything. Some professions are much more variable than others, and the length of the tail varies a bit as well. In general, most people identified 10 or fewer tools, but there were also a couple of overachievers who ticked off all 23.
Another interesting thing to keep in mind here is that there’s a behavioral component to this data, as well. I’m sure there were a few people who picked only one or two tools, even if they have used many more in their career, and possibly others who dutifully checked off every single tool they’ve ever used. There’s probably some aspect of prioritization, frequency of use, and expertise/familiarity with the different tools that’s not captured here, and there may also be a gap between the tools that people use professionally and what they use in their personal projects. If someone is working on a team, they may not personally use d3.js, but it might be the final form for all of their work. To really get at those details, we’d need to add several more questions (and a lot more complexity) to the survey. It’s always good to keep in mind what questions you can and can’t answer from the data, and where your interpretation starts to run up against the limits in the information that you have.
Another way to get at a comparison between groups is to do a median calculation; the median bin is shown as a teal dot in each bar chart above (I’ll work on the visual representation later), or I can count up the median bins and make a derivative histogram showing the median number of tools for the different professions. For most professions, the median falls between 4 and 5 tools, but there are a couple with medians as low as 2 or as high as 7 tools as well. I would want to look closely at those edge cases in the final analysis, just to make sure that I don’t have a hidden n-value problem giving me unrealistic medians or otherwise skewing the results.
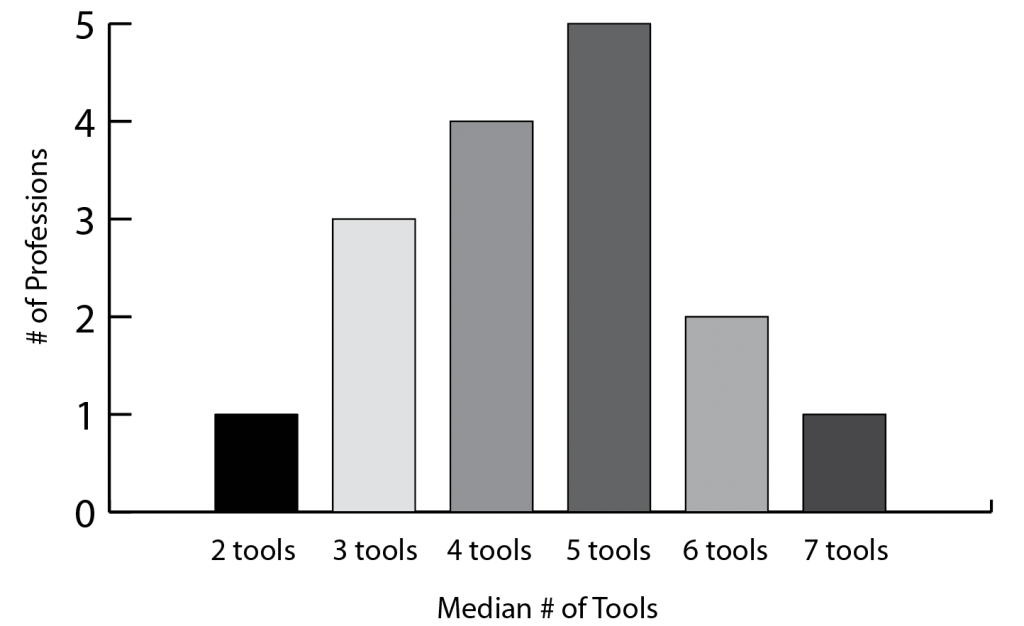
So those are the simple count calculations that I can get from the most basic analysis of this dataset. Next time, we’ll start looking for ways to get at correlations between tools, to understand more about how pairs of tools can be used together.
1 thought on “Pivot to Tools”