This post is part of a series focused on exploring DVS 2020 survey data to understand more about tool usage in data vis. See other posts in the series using the ToolsVis tag.
As this exploration continues, I’m working my way deeper and deeper into the data, trying to get to an understanding of which tools people use together. I’ve tried collapsing the data down into branches by grouping people with identical tool sets together. I’ve tried collapsing each person’s tool set into a list, and then comparing their lengths. Both of those approaches produced interesting results, but they didn’t really get at the heart of what I’m going for, which is a picture of how different tools cluster together. This might sound frustrating, but I find that it’s often the most exciting part of the analysis for me. I think of it as pacing around the edge of the problem, sizing it up and trying to find a way in. I’ll make a gambit, fail, and then step back to a neutral place and pace around it again, using that new information to test for other methods to approach the problem. This is where the deep problem-solving happens, and usually where the real challenge lies. It takes patience and persistence and a tolerance for many failed attempts, but this phase of a project is usually where I am most interested and engaged in the puzzle.
When the branching analysis didn’t work out for a second time, I went back to a previous iteration with a correlation matrix and started working forward again from there. I still wanted to use the number of tools in a group as a reference, but I wanted to focus less on the branching relationships within each one. By focusing on the total count of tools that people use, I was then able to calculate the distribution of users for each one. In this version, people who use just one tool are in the first column: you can see right away that Excel and Tableau dominate that group. If you read across a row, you can see how many people use 2, 3, or 4 tools. Reading down a column, you can see how many people in the group with 5 tools use d3, Illustrator, etc.
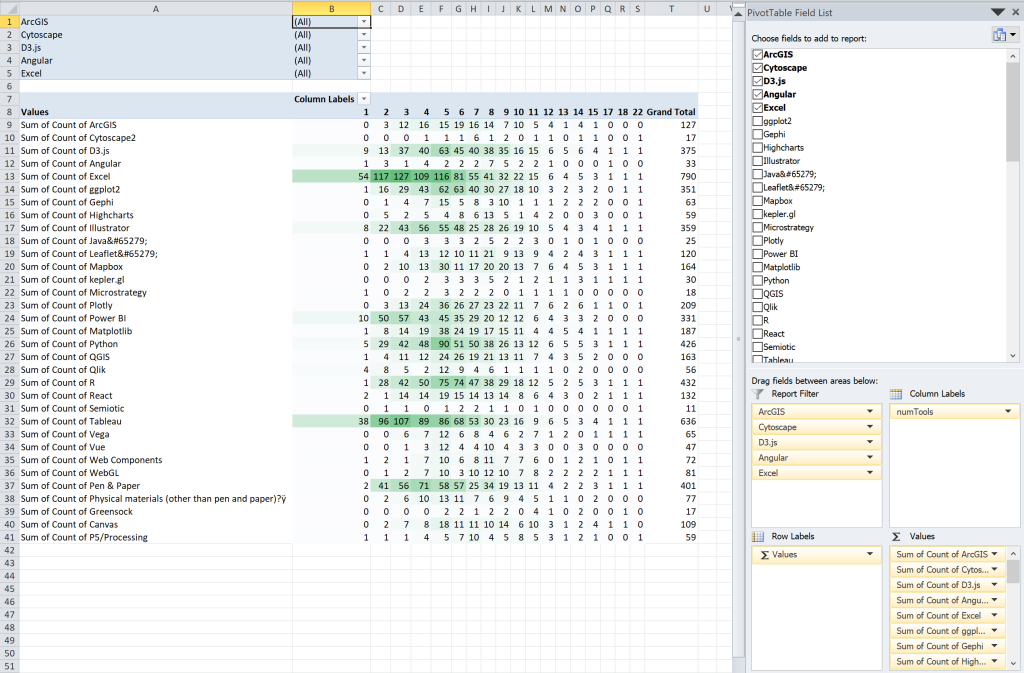
This is getting a little closer to the information that I want, but it still doesn’t tell me which other tools people are using in their group of 5 tools. Ideally, I’d like to see the distribution of other tools used for each cell in the table (part of what started me down this part of the exploration was thinking about how to build out data for a treemap). I can get at some of the information that I want using a filter. Here, I’ve selected the people who use ArcGIS in the first filter, and the people who do not use Excel in the last filter in the list.

Now, the table shows me the distribution of people who use other tools in combination with ArcGIS and who also do not use Excel. This is getting into the kind of logic that I want, but it’s sort of like using a microscope when I want a wide angle lens. I’m really looking for more of an overall picture of the tool space, rather than an item-by-item granular view. I could get to the macroscopic view by iterating through all of the combinations of tools and storing off the filtered results for each one, but there are 34 total tools in the data set (including “other”), and combinations increase as a factorial of the number of tools (2.95e+38), so that’s not a task that I’ll be doing by hand. I’m lucky that most people don’t use more than a few tools and very few use more than 10, so most of the combinations are not populated and the factorial is not actually as bad as it sounds, but still. This one will be much better done with automation and actual analysis software, so I’ll put a bookmark in it for now and come back to it in the next round.
As I’m getting deeper into the analysis, I’m also starting to build up a stronger sense of what I’m trying to achieve with the final visualization, and getting a feel for the information that seems most important to me. As those things become clearer, I’m starting to think about what form I want the visual output to take, and what kinds of analysis and tasks I want it to support. That will shape not only the form of the visualization, but also the tools I use, the approach I take, and where the analysis has to happen. A visual focused on filtering and drilldown is very different than one focused on a macroscopic view. If I’m building something that uses a bunch of filters in a web browser, it may not be worth doing the full analysis and then uploading the data; it might make more sense to do some of the aggregation calculations on the fly in Javascript, rather than trying to compile and calculate them all here. If I care more about the high-level view, then I may not need all of the granularity (and corresponding effort) to break out the individual parts.
I’m not interested in optimizing the specific visual form just yet, but I am starting to think about some of the shapes that the data might take, and what that means for how I do the analysis.

I could start out with units (drawn as bubbles here) to compare the popularity of different tools. I could define those by tool pairs, instead of individual tools, and even add in some secondary grouping if I wanted to. If I choose (or allow the user to choose) a reference tool, I could add in connections to show some of the pair relationships as well. Those could be organized by some additional logic, or they could have different degrees of separation. If I want people to be able to identify sequences and relationships between groups, I might need some kind of additional connection type that allows the groups to circle back on each other, forming a closed set, or a loop. Or, I could let them branch off indefinitely, and not worry about reconnecting. All of those things will change what structure the data requires, what needs to be built into the final data objects for visualization, and how I want to approach my analysis.
Most of my ideas at this stage don’t make it into the computer, or even into the Excel analysis, because that would take too much time. Instead, I fill up notebooks full of minimal sketches – just trying to capture an idea with enough detail that I’ll remember it, and nothing more. Sometimes I’m trying to think through how multiple steps in the analysis will work; other times, I’m considering the organization and limitations of particular forms. Some of the sketches are warnings about the pitfalls of a particular approach, and some of them are questions about what’s really important in the data. The point here is just to think through the sequence and questions, and to understand what kinds of connections I need to provide for someone to be able to see what I want them to see.

1 thought on “Recalculating…”