Re-incorporating the land use data from my original poster is the last major component of the thesis site that needs to be roughed out. I had started working in this direction at the beginning of my Studio3 class last fall, and even developed a quick-and-dirty dashboard to visualize the data completeness, but it became clear pretty quickly that that dataset wasn’t going to meet the class requirements very well, so I made Food Flow for that class instead. Unfortunately, that leaves me with no visualization of the land use and population data, which is a pretty central part of the soil story, and one that I really want to tell as part of the thesis site, so over the past week or two I’ve been working on finalizing that design, incorporating a couple of other datasets that I think help round out the country comparison.
I was never fully happy with how the trade balance page of the Food Flow site worked out; there were lots of small things about it that bothered me, and it never quite seemed to fit with the rest of the design for that visualization. I had been thinking about removing that tab altogether, and thought that this new visualization could be a good place to include the trade balance data, in a more readable bar chart form.
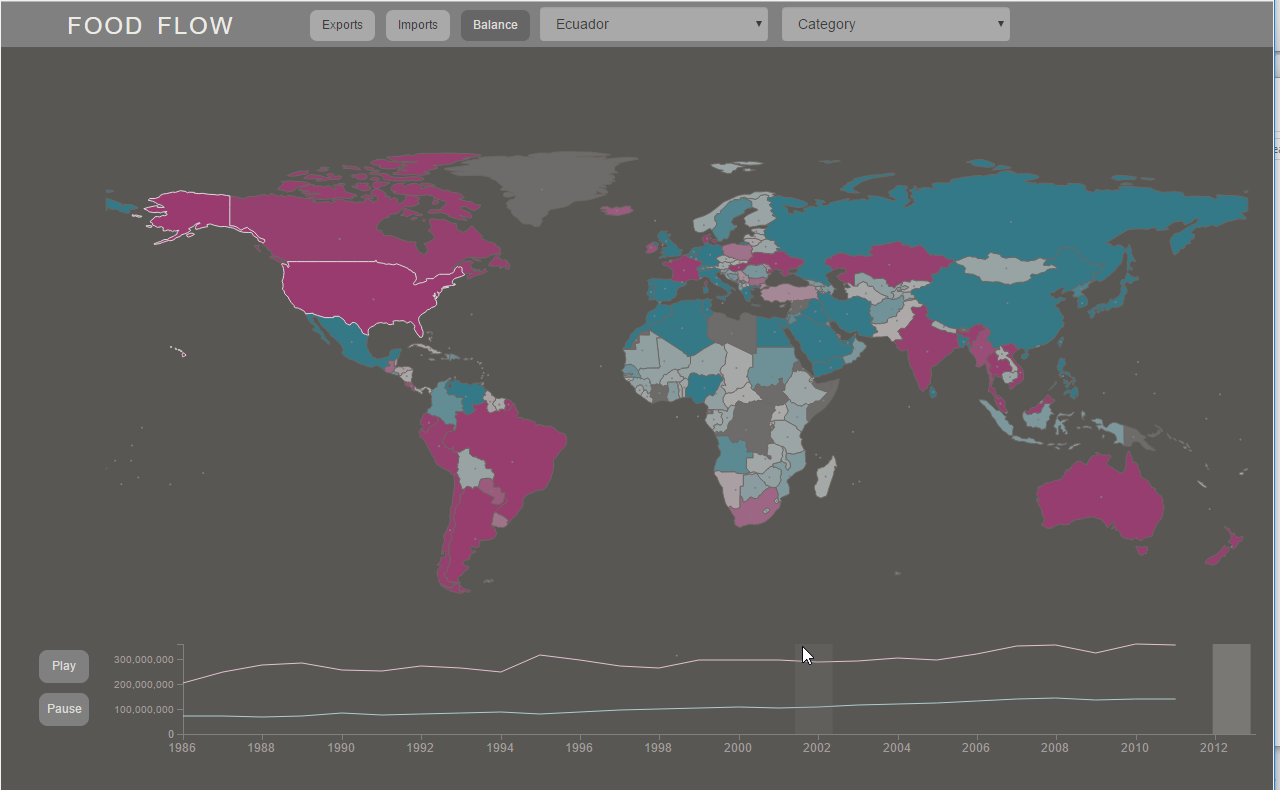
I also found a new dataset back in January that tabulates information on how much people in different countries eat, and calculates the per capita land requirements to grow enough food to support populations living in different regions of the world. I think that dataset is really helpful in tying this whole story together, so I’d like to include that as well.
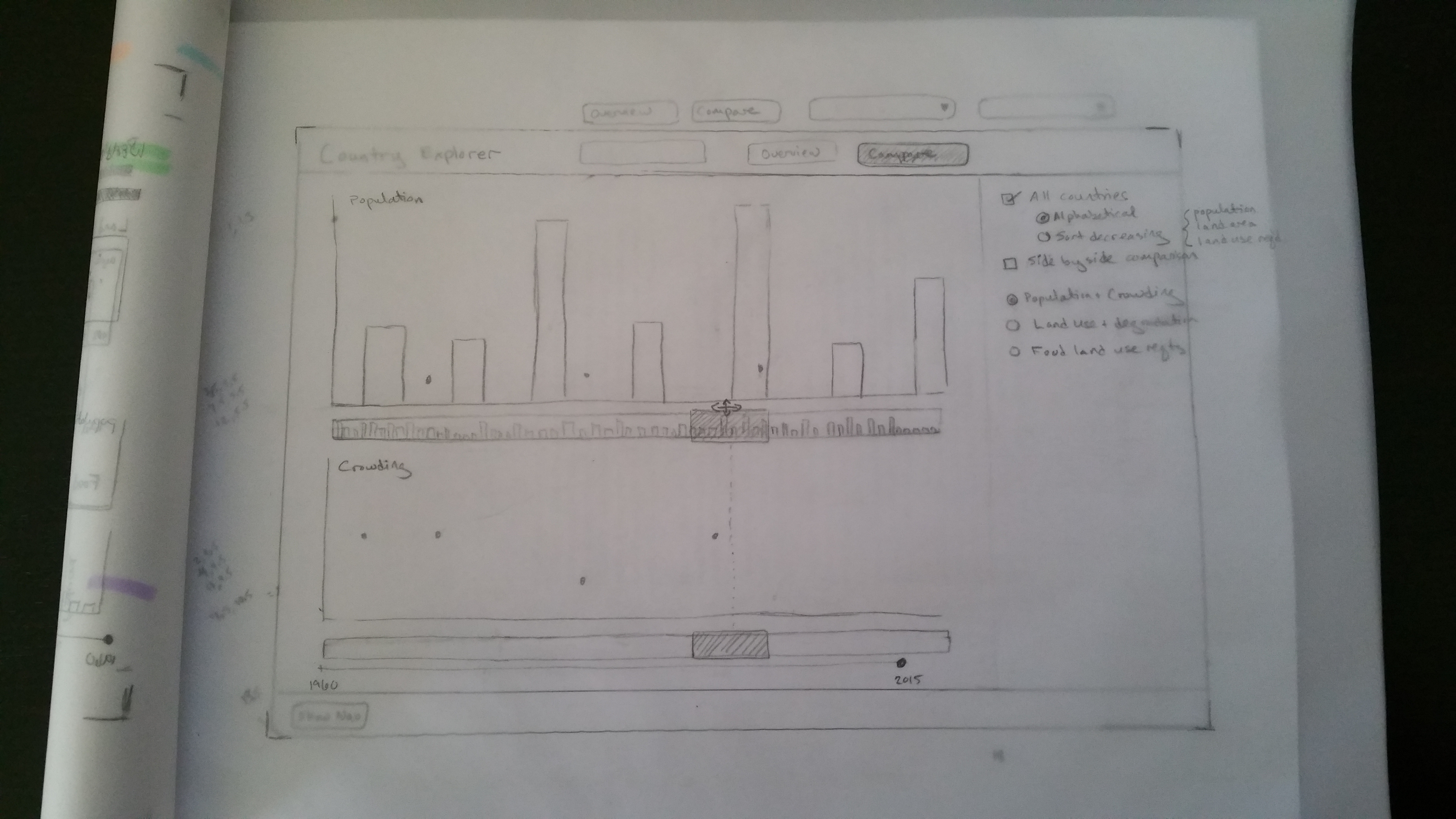
I met with one of my thesis readers last week and had a very productive discussion about what kinds of data views would be most interesting, and how to slice up the different components into helpful views. After that meeting, I sat down with some tracing paper and a pencil (my favorite tools for multi-page web layout – faster than drawing in Illustrator, and easy to work through multiple views), and started sketching up some ideas.
The front page had a few navigation buttons in the top menu bar, and then shows a view of all of the different variables for a particular country in a single year. I plan to start this off with information for the entire world, and then allow the user to select a particular region or country of interest to drill down.

I don’t have a lot of screen real estate here, but my original poster layout was pretty compact, and I am hopeful that we can fit the different pieces in. From top to bottom, the sketch above gives the total population, percent land use for each of the major categories, amount of degraded land, crowding (people per sq. km), food trade information in two bars – one showing imports and production values, the other showing exports, consumption, waste, and non-food uses, average caloric intake, and finally a comparison of the actual land available in that country/region, and the total amount needed to support the population’s food needs. Finally, at the bottom, I planned to include a time slider that would allow users to browse all of the years in the dataset, with a play button that would auto-advance so that they could watch changes happening over time.
The next page would allow side-by-side comparison of two countries, with the ability to select between different pairs of related variables – population and crowding, land use and soil degradation, and food and total land requirements for the countries. The top section of the page focuses on visualizing a single year in the same format as they are shown on the front page, and the bottom section shows the same data as a line or bar graph over time. Time sliders at the bottom would allow you to compare values for the same country in different years, or for two countries in the same year.

Finally, I hope to include a ranking page that compares all of the countries in the dataset, and lists them in order according to user-chosen filters. This is for the people who only want to see the top or bottom 5, and don’t really care about the rest. I’m hoping to use a format similar to the one I used for the world population data, which use d3’s brushing and linking functions to show an overview of the entire graph in a small menu visualization, while the main display zooms in on a selected region to show more detail.
This is an awful lot of programming to pull of in not much time, but I’m hopeful that I can manage it. I have a lot of the different pieces figured out already in other sections of the code, and I’ve done several projects with successive filtering and data updating, so I think I *should* be able to get at least the basic framework put together pretty quickly if I really push.
On Friday, I sat down and roughed out the front page. I figured out how to add the navigation components to my page template dynamically, imported and filtered the data and used it to populate the selection menus, and wrote up the basic drawing functions for showing the data on the screen (the gray dots are just positioning guides that I’m using for determining relative placement of the different features).
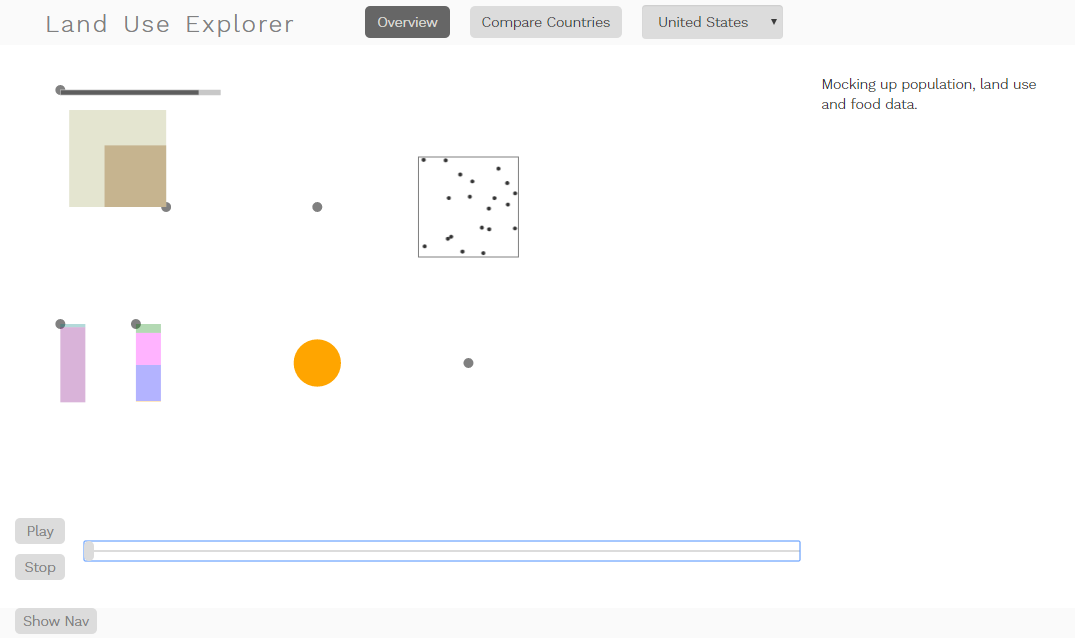
I also came up with what I thought was a really clever solution for a persistent problem with the crowding data. Each of the spots inside the square represents one person per sq. km of crowding, and some countries have a lot of crowding. Singapore is the worst, with almost 8,000 people per sq. km. Since each one of those spots is a new DOM element, that makes d3 very slow. That wasn’t such a big deal in the printed poster; it took a long time to render, but since it wasn’t intended for live viewing the delay didn’t matter much. Here, however, it’s a real problem. I could put a canvas behind the svg and plot the points there, but plotting 8000 points in Javascript would cause a noticeable delay, even if they’re just writing to the canvas.
Fortunately, when designing the site index page a few weeks ago, I figured out how to import pictures into d3 DOM elements using patterns. This seemed like the optimal solution; have d3 pre-generate all of the images, and save them as a bunch of tiny .png files that could be loaded from a function call. That part worked great. I wrote up a version of my code with a click handler attached to the svg background, and then Branden used AutoHotKey (his favorite scripting language) to take a cropped screenshot of the image, save it, and then click on the background to advance to the next number of randomly-generated spots. Quick and relatively painless, and a few hours later I had 8000 image files that cover my entire data range and can be loaded on demand. Perfect, right?
Well, no. The images do work exactly as advertised, but once the visualization was live I found it really distracting to have the crowding squares changing all the time. It’s also really hard to tell whether new spots are being added or whether they’re just randomly moving around. It would be much better to have the same arrangement of spots and just add one or two at a time, as the data requires, rather than having randomly generated positions. Of course, that would require having a static set of images that increases one at a time. I’m still working out what to do about that one, but I think you’ll see why it’s a problem in the video series below:
I also learned several other useful things from the mockup. The first is that the land area change isn’t terribly obvious, partly because of the area scaling, and partly because of the gradual changes over time. Not surprisingly, it’s also difficult to know which kind of change to pay attention to, especially since they happen in multiple directions at the same time (the population bar grows to the right, land area to the upper left, crowding stays the same but the spots move, and the food bars grow down). I thought that this was likely to be a problem before I programmed it, but I also wanted to get a sense of what the different variable changes looked like side by side.
Another issue was that the degraded land area is only available for a single year, and actually represents the amount of change over an interval of years, rather than the total final amount. And, as I knew from earlier experimentation, the land use area boxes pop in and out, depending on whether or not data is available for a particular year. Most of these are known issues, but it was helpful to see how the different pieces functioned together, and helped me to get a better sense of what I’m trying to show. The good news is that I think I can fit these different components onto the screen; the bad news is that the changes aren’t really visible yet. In the final version, I plan to show a static version for the front page, showing all of the variables for a recent year where there is complete data, and to reserve the time sliders for the simpler variable-by-variable comparisons in the second and third page.
I started adding radio buttons and checkboxes for the second page this morning, and Branden is reshaping the data file for me to simplify sorting and indexing, which should simplify the code and improve the page loading time and update speed. I split everything up into separate update and draw functions, and started adding tracker variables to check which user inputs are selected for the different modes. I also made different positioning options for the different modes, so that the visualizations can rearrange themselves from one organization to the next, depending on which mode they’re in. Next, I need to connect these different drawing and update functions to the compare button, and make sure that they play nicely together. From there, it should be fairly simple to add the longitudinal plots and the dynamic bars for the final page. Hopefully in the end I’ll have a multivariate viewing system that can help to guide viewers through their explorations of the data story.