I’ve been working on a first draft visualization of world population data today. Over break, I took a step back and looked at the stories I’d like to tell with the soil data, to get a better sense of where to focus for the months ahead. The first revelation was that it’s going to take a lot of visualizations to tell this story the way I’d like it to be told. I have a few pieces done, but there are huge gaps left, and they need to be filled. One of my many goals for the next few weeks is to mock up a bunch of fairly simple visualizations as placeholders that can later be developed into more interesting visualizations.
The story is about humans as much as it is about people, so human population is a critical issue in pretty much every version of the narrative. I found some historical population data from the Census Bureau over break, and manually assembled a list of relevant historical events for the timespan covered. This morning, I sat down and started to prototype.
It was pretty amazing to see the shape of the simple population curve. I knew intellectually that human population had grown explosively in recent years, but I don’t think I had any real concept of just how much bigger it had gotten. This graph shows estimated values from 10000 BC to 2050. For most of human history, the world population was a few million (not even visible on the graph). There’s a tiny bump around 1000 BC, and then the population gradually increases until about 1800, where things really start to take off. That tall spike on the right shows the expected population increase in the next century, and the size of it is staggering. Just one of those cases where a picture is worth a thousand words, I guess – seeing the data mapped out this way gave me a very different sense of the issue than I’d had before.

The time scales are pretty vast here, so I also wanted to give some landmarks to help provide a sense of scale. The plot is based on a simple d3 brushing example, so the user can change the date interval measured pretty easily. Incorporating some historical events should help to highlight some of the trends that I want to bring out, and also to orient people to this long history.
I started by just adding a line for each event in my spreadsheet, to see what the distribution looked like. Right away, there are some problems with this. Because much of the ancient data is approximated, people tend to give nice round numbers, which means that many of my lines overlap at the century markers. I think I want to include mouse interaction with individual events, so I need to figure out how I’m going to deal with this in the long run – having a bunch of lines on top of each other won’t work.

I’m pretty sure that I’m going to have to write my own line spacing function at some point, but I wanted to do a little exploration and see what the data looked like first. My first approach was to see if I could reasonably spread out the lines by adjusting their x positions. Spreading out the lines gives a much better sense of the count of events at each point, but it’s still pretty crowded around the century intervals. This is pretty likely just an artifact of the data, and evidence of a rounding problem; not surprising when working with data that has such low accuracy.

For this mockup, I adjusted the line positions manually based on the values in my spreadsheet. The minimum line width is a single pixel, which means that the lines have to be 30 years apart to be visually distinct at the most zoomed-out level. Because the separation is manually set, it stays the same on zoom, which gives the (false) impression that the date differences are real. Linking the line spacing to the brushing zoom level would help to reduce this issue, and give a better representation of the data.
I think I will likely also incorporate semantic zooming to reduce the number of lines in the final version. At the fully zoomed-out view, I would show just a few of the most important lines, and then increase the number of details as the user zooms in. To see what that might look like, I tried assigning priorities to the different events, based on my ideas of their relevance to my topic. High priority events became a little bolder, low priority events a little lighter (these would be turned off at this zoom level in a semantic zooming system). This helped a little, but there are still places with very high event densities that will need to be dealt with.

Next, I wanted to look at the distribution of different types of event across the time period measured. I handpicked events for the timeline that were specifically related to agriculture and human population. Early on, this means a lot of “firsts”: first record of agriculture, first record of seed storage, first evidence of livestock, etc. Then, there are a lot of cultural/historical events that help to frame the history; settlement of Egypt, founding of Rome, things like that. Once we get into more “recent” history, there is also a lot more data about plagues and famines, which are important because they’re related to population loss. In the modern period, there is also a lot of technological advance, with things like GMO crops and industrial fertilizers showing up on the scene.
To get a better idea of how these different categories clustered through history, I gave each of them a color. As before, heavy lines show high priority events in each category, and lighter lines show lower priority events.
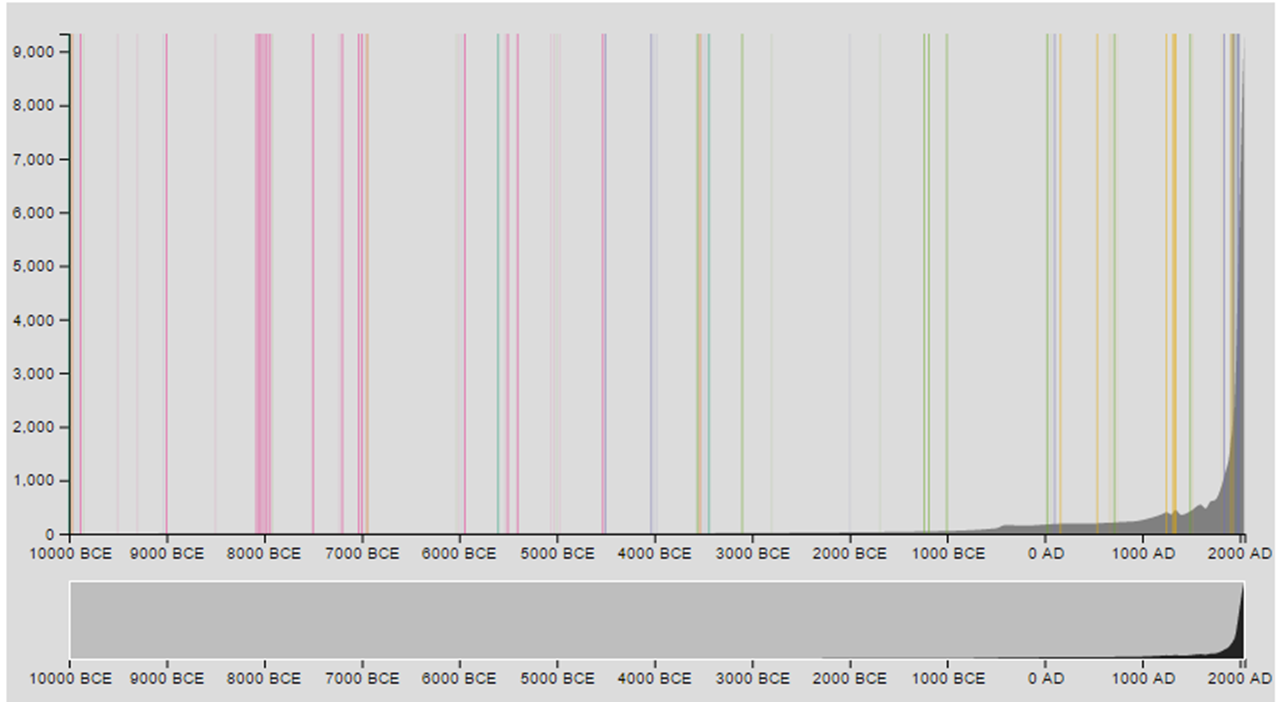
As expected, there’s pretty clear evidence of a selection bias in the data here as well. Of course, I made a judgment call about each and every piece of data that I included, so my own biases and interests are strongly represented. But it’s a matter of incomplete data, too: we don’t know much about plagues and famines in 8000 BC, so that information is heavily biased toward periods where we have better records. If your whole sense of history were based on this particular graph, you’d get the impression that wars and famines have become much more common in the past 1000 years. That’s partly true; increasing population means more chances of clashing with your neighbors, and the invention of cities, trade, and now global travel have made us more vulnerable to widespread disease. But modern medicine and agriculture have also minimized the impact of diseases and famines, so their effects are not as devastating as they once were.
I’m not sure that these selection biases are a problem for this particular visualization, since the events shown are intended to provide interest and a general sense of context rather than to support a scholarly argument. But still, it’s important to note how much my choices change the conclusions that a person might draw from this graphic.
I also thought it would be interesting to highlight the different kinds of data present in the population dataset. I don’t have any measurement/estimate for the uncertainty in this dataset, but would expect the following to be true. Most of the really ancient data is based on archaeological estimates, which are very imprecise. Even if the data is good for a particular civilization at a particular moment in time, there is nothing like a global population count that’s reliable. Because the size of the population itself is so much smaller than in modern times, the scale of the graph minimizes the effects of these variations in the older data, but they become more apparent when you zoom in. It’s tempting to try to attribute each peak and valley to some population growth or disaster, but it’s much more likely that they’re just artifacts of the datasets used to construct the curve.
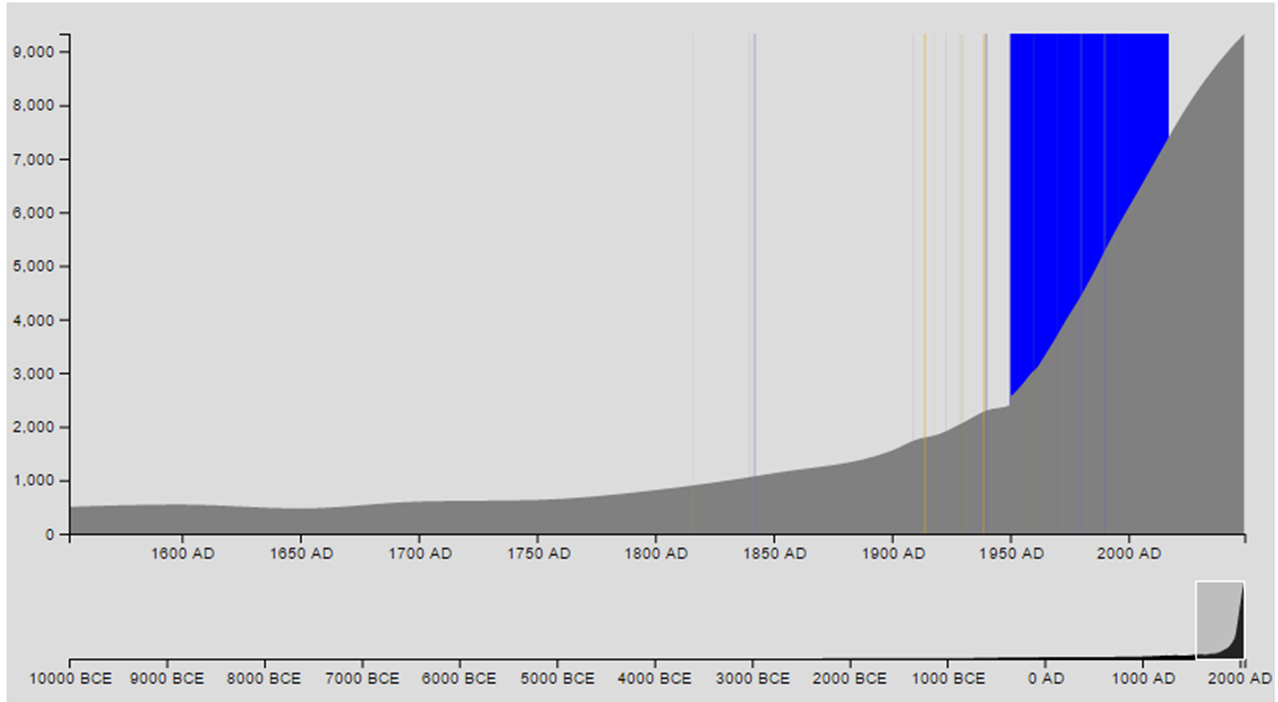
The data gets better and better as we approach modern times, because tax records and other government reports help to supplement other ways of guessing populations for different places. Universal records have only been kept for about the past 50 years; the population numbers for the UN and Census Bureau data only go back to 1950. There is probably still some uncertainty in this section of the dataset due to differences in how countries report their numbers, but for our purposes it’s pretty safe to call the error in this period close to zero. After 2017, everything is based on numerical models, which have their own uncertainties as well.
To help myself visualize the different data qualities, I added a highlight rectangle behind the dataset for the years where we actually have good data. The window is so narrow that I had to make it bright blue to be able to find it at all.

Zooming in, it seems a bit more significant, but in the scheme of things it’s still pretty small.
So far, I’ve only been looking at the lower series of estimates for the population data. The Census Bureau dataset does contain the original data sources, as well as an overall upper and lower bound for the estimates. The estimates from the original datasets vary widely, and they don’t cover the same number of years, which leads to a lot of fluctuations in the dataset. If one person tends to estimate high and they’re the only one represented in a particular year, there’s an unexpected bump in the data that probably doesn’t really exist. There are also years that are particularly low, that represent the opposite scenario. Plotting the second set of data behind the first helps to highlight some of these differences, and probably gives a more realistic sense of the variability in the data.
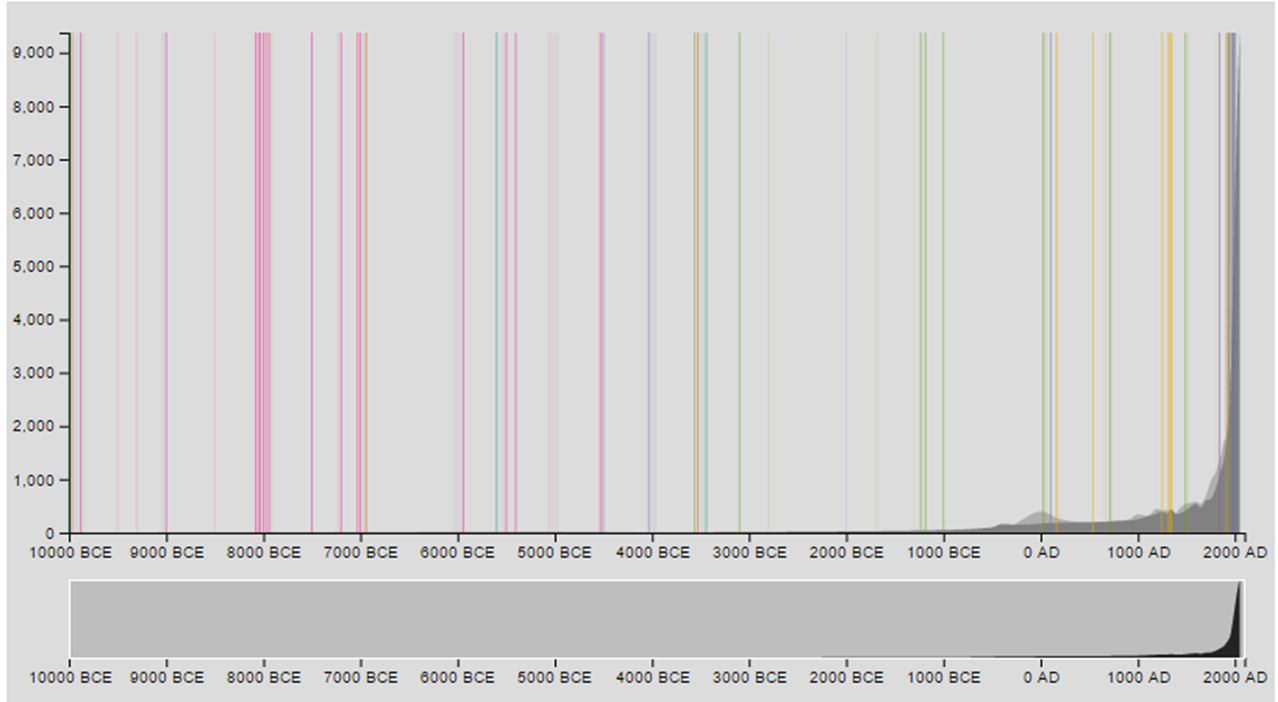
This data seems like it could be a really good opportunity to experiment with designs to represent uncertainty, which I feel is one of the key requirements of designing for scientific communication. Even in this simple exploration I’m seeing several different issues emerge that are important to consider, and I’m sure that there are more I haven’t noticed yet. At the highest level, this plot incorporates uncertainty due to missing data, different estimates, forecasting and modeling, and reporting and sampling biases, among others.
My next focus for this visualization will be to figure out how to display and label the event lines, but it would be interesting to lean further into this question of representing uncertainty, as time allows.