We covered a lot of ground in the VizTech class last semester (my git repositories are here, if you’re curious). Starting with basic HTML and CSS in the first couple of weeks, we quickly moved into writing conditional statements and loops with Javascript, as well as importing and accessing data. By the 4th week of the semester we’d started experimenting with the d3 library and had been introduced to the enter-exit-update pattern that makes d3 so powerful. We made simple drawings of circles and squares and set their properties to understand object constancy, and then began a deeper exploration of the data bind.
Among other things, we:
- drew scatterplots, pie charts, partition diagrams, treemap layouts, force layouts with collision functions and custom gravity, and a dorling cartogram
- created line fits using a path element
- implemented tooltips and interactivity.
- mapped census data to learn how to navigate geoJSON and JSON data structures
In 13 weeks, I went from knowing no HTML, CSS, or Javascript to being able to fumble my way around all three. I’m definitely not an expert yet, but I am beginning to have a pretty good idea of the shape of things in d3. Negotiating the data bind was probably the hardest thing for me to grasp; it’s very different than any other programming that I’ve done, and it took a while to get used to the idea, but it is pure magic once you get it. It was very interesting to play with this powerful piece of software, and to learn about the kinds of things that it can do.
For our final project, we were assigned to choose a dataset and create a d3 graphic using some of the techniques we learned during the semester. I chose to work with census data, and downloaded the appropriate .csv reports by hand from FactFinder and CensusReporter. I defined a nested .json format for the data, and Branden helped by writing a script to construct a dataset for analysis from the .csv. (I just found out on Monday that my Research Methods class is going to cover data scraping this semester…that would have been useful to have before this project!)
I wanted to use my visualization to explore the variations in commute habits for people living in different cities. I chose to work with the ten cities with the worst commutes, as a mostly-arbitary way of narrowing the field. The full animated version is here, but in order to talk about the design (and as protection against the vagaries of scripts and browsers), I’ll also insert screenshots below.
I wanted to create an animated visualization that would show increasing levels of complexity in the census data, but I didn’t want the viewer to have to sit through the whole animation multiple times if they wanted to repeat a particular section. So, I divided the visualization into 5 separate frames that could be viewed separately and in any order. (This turned out to cause other problems, but we’ll get to that later…)
I also didn’t want a large amount of text analyzing the dataset, since the animation should be doing most of the work. To help orient the viewer, I added labels that updated to reflect the kind of data being viewed at any given time, and then used the animation to layer on additional symbols in several steps.
The visualization began with a simple plot of the average commute times for different cities. The area of the bubbles reflects the city population (this was indicated in a previous animation frame). The lines through the circles indicate their position on the y-axis, which presents the average commute time.
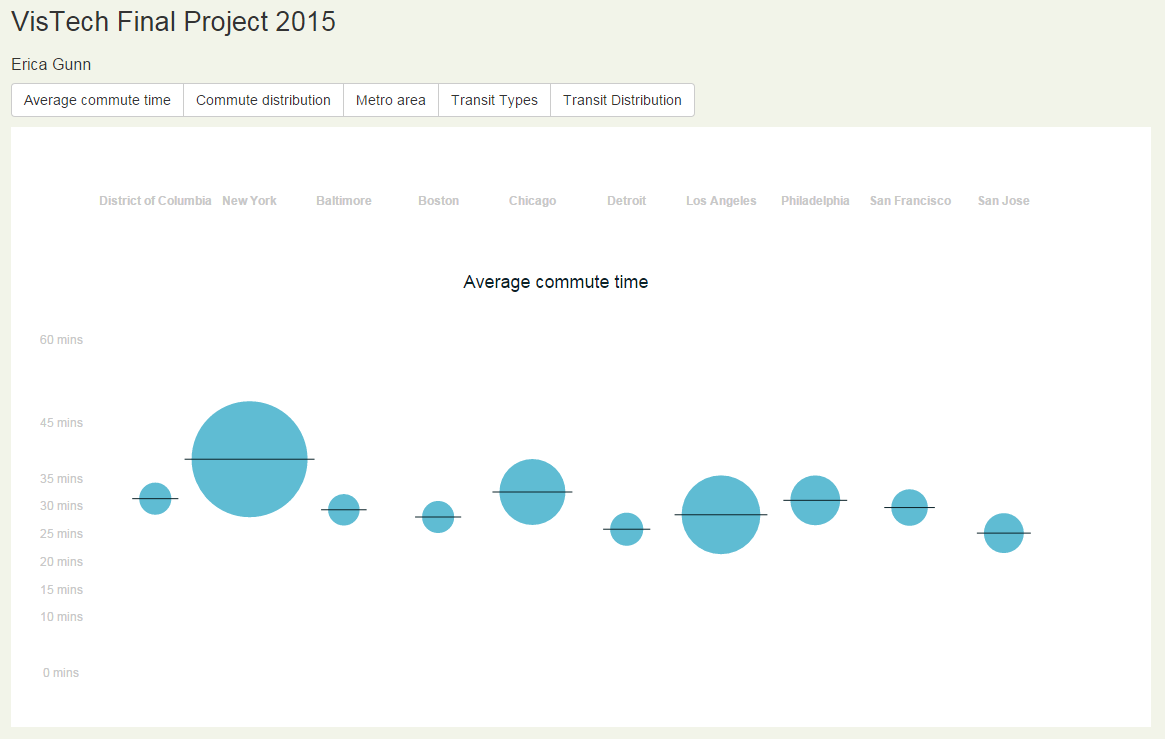
The next segment of the animation showed the number of people who commute in each city (dotted circle), followed by the number of people whose commute times fall into each of the census bins, giving an overview of the distribution of commute times for each city.
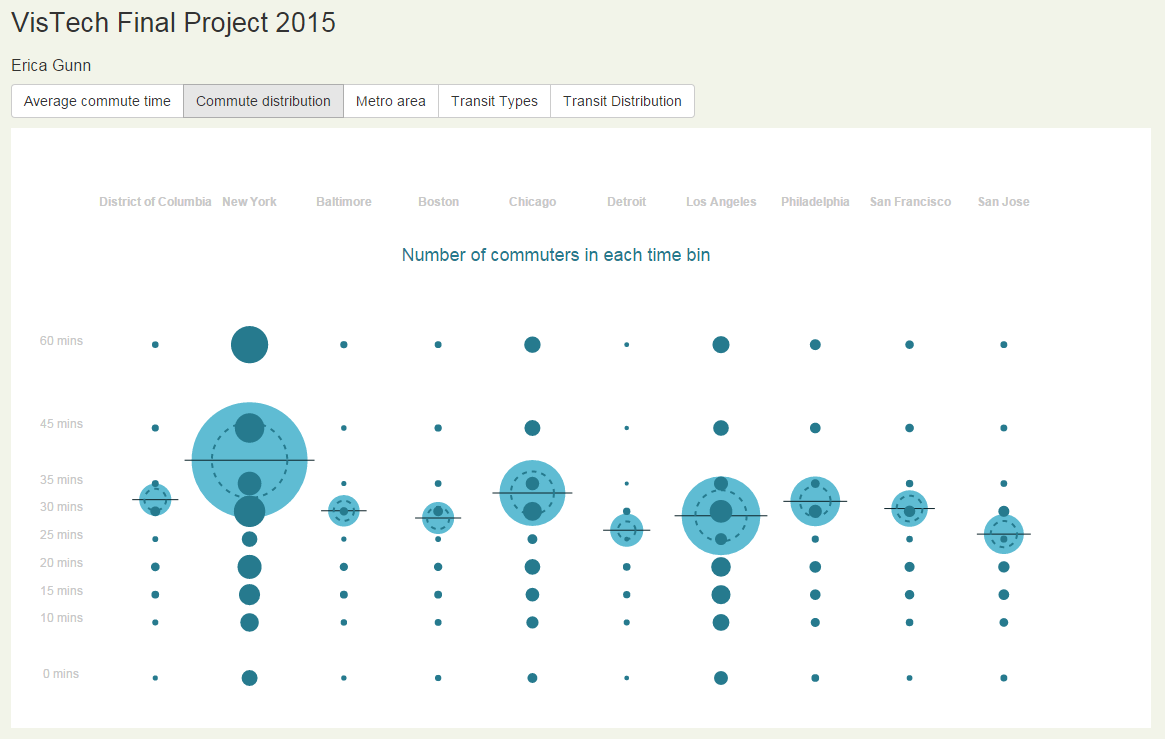
I debated for some time about the best way to show this information. To compare city to city, it would be easier to look at the commute distributions scaled to a common value. The original implementation had all of the cities scaled to be the same size, which allowed you to read across the chart for any time bin and see which cities had proportionally more or fewer people in that time bin, relative to the city size.
I didn’t want to confuse viewers with the transition from relative city populations to scaled commuter distributions (where all city populations would be scaled to the same size), so in the final version I used the absolute commuter counts to determine bubble size, rather than scaling them. This does make city-to-city comparison somewhat more difficult, but I think that the smoother transition was worth it.
Next, I wondered if the city commuter population matched the commuting reality for all cities. Boston is a small city, so people who live and commute to work in the city have a smaller distance to travel than commuters in, say, Chicago.
The next frame of the visualization presented the metro area population of commuters to facilitate this comparison. (Unfortunately, this report was not available for the DC metro area, so it is not included.)
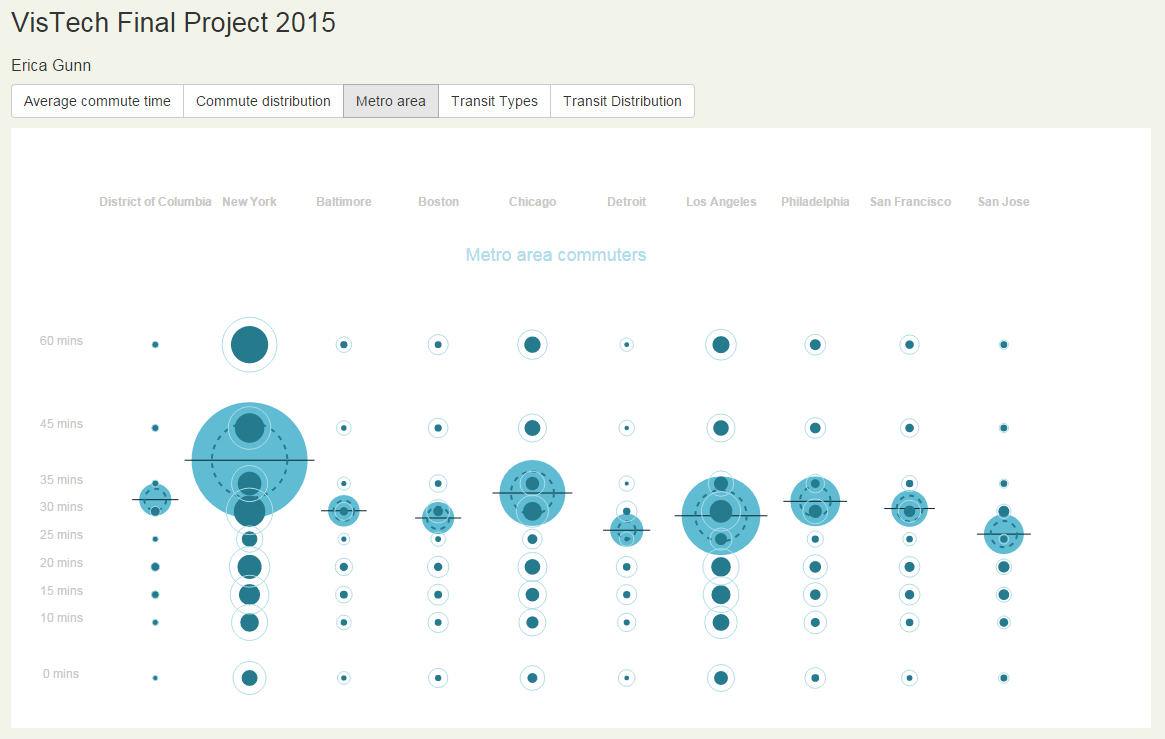
I was actually surprised at how little difference there seemed to be between the city commuters and the metro area commuters. The metro area values were of course larger in general, but the pattern of commute times didn’t vary as much as I might have expected.
Next, I wanted to see how the commute times broke down by transit types, to get a sense of the different methods that people used to get to work in different cities. For this, I used pie charts positioned at the average commute times for each city, echoing the pattern established in the first population graphic.
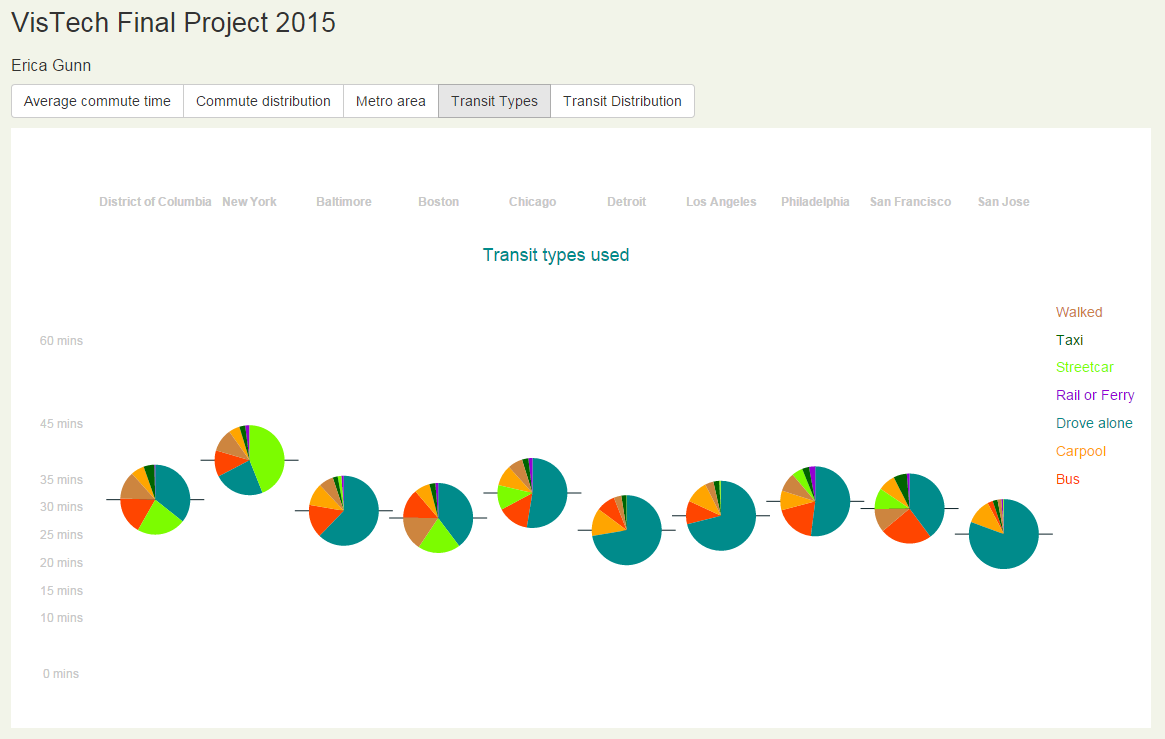
This was one of the more interesting graphics to examine. It is immediately clear that there are large differences in the kind of transportation used in different cities. Unsurprisingly, Detroit, Los Angeles, and San Jose have a lot of drivers, which New York, DC, and Boston had a lot of people who use streetcars. (Based on the numbers in the data, I believe that commuter rail systems count as streetcars for the purpose of this survey, and that rail is reserved for services like Amtrak. I didn’t find that documented anywhere, but it seems to be consistent with the magnitude of the data.)
Next, I wanted to visualize how commute times compared across different transit types. I had originally used equal-length bars to represent the average commute time for each transit type, but Siqi suggested that I scale the length of the bars to reflect the width of the wedges in the pie chart. I do think that approach does a better job of encoding all of the data, but I’m not sure what I think about its effect on the aesthetics and readability of the graph. Since some of the numbers are very small, it can be hard to find or identify the color of the shorter bars.

At first glance, I was interested to note that all of the public transit appears above the average commute time, and that driving is always at or slightly below the average. Carpooling doesn’t seem to make much of a difference in most cities, but in New York and San Jose it seems to be a relatively large disadvantage. Only DC and San Francisco showed carpoolers coming out ahead of solitary drivers, on average.
It’s critically important to emphasize that “on average” caveat for this data. I wasn’t able to get tables that gave raw data for the commute times of individuals; all of the data presented here has been binned and presented in the aggregate. And none of the binning attempts to correlate one variable to another. This means that I have no way of telling the difference between a person who commutes 2 miles in an hour and a person who commutes 40 miles in an hour; both of them get added to the counts in the hour bin, regardless of distance.
This is especially important when trying to draw conclusions about commuting habits based on the last graphic. If you took this data at face value and did not consider that the marks represent only time (and not distance), then you would naturally come to the conclusion that public transit is terrible, and that walking is the fastest way to get to work. Walkers consistently beat the average commute time by more than 30%, but that’s not necessarily because it is always faster to walk than to drive.
If you consider the effects of the missing distance information, then the reasons for this discrepancy become clear. People who have shorter commutes tend to walk, and so they get to work faster than people who have longer commutes. In order to tease out the real advantages and disadvantages of taking the bus or carpooling versus driving, you’d also need access to both the commute distance and time information for individual commuters.
This project was definitely a challenge, but it was interesting to take publicly-available data and find out what was in it. The limitations of the data meant that I couldn’t draw the kinds of robust conclusions that I would have liked, but it is an interesting problem to consider, nonetheless.
I imagine that this particular aspect of working with data will come up again and again in information design. In science, when you find something like this you just go back and measure it. When working with publicly available data, that isn’t always an option.
I would have liked to include tooltips and interactivity in this assignment, but getting around various stumbling blocks in the coding took up a lot of time. I am pretty happy with the individual visualizations in the final product, but there’s one piece of the code structure that still bothers me.
As I said above, I divided the animation into 5 different visualization frames that the viewer could access by pushing the buttons at the top of the screen. Each function expects certain pieces to be on the screen already when it begins, and that created instability in the user interface: if the buttons were pushed in the wrong sequence, then some parts of the animation didn’t work.
I tried several different ways of getting around this, but never got it to work to my satisfaction. I tried talking to Siqi a few times in the weeks leading up to the project due date, but he was swamped with work and student questions and didn’t have time. In the end, I created 5 different functions that executed the separate graphics. When the user clicks a button late in the sequence, the browser simply runs the previous functions as quickly as possible and then continues on with the display.
The loading delay is not terribly noticeable in most frames unless you’re looking for it, but it does add an annoying jiggle to the beginning of each animation frame. I’m hoping to spend some time working on a different structure to get around this, but need to find someone with more d3 experience to talk through the options and discuss the pros and cons. I’ve completely refactored the code 3 or 4 times already, but haven’t managed to figure out how to work my way around that one (yet).
Overall, though, this was a good project to solidify skills learned throughout the semester, and to experience the joys and frustrations of real-world programming, rather than working only on class exercises.