My p5.js class with Pedro Cruz has been working on building a visualization of the CrunchBase database, which gives a list of major companies and who has invested in them. We started the class by building the basic program structure together in a working-group format. At the beginning of each class, Pedro would list a series of tasks on the board, and we would work on them individually or with our neighbors, while he came around to answer questions. This semi-structured approach then gradually diverged into individual projects focused on creating our own versions of the visualization.
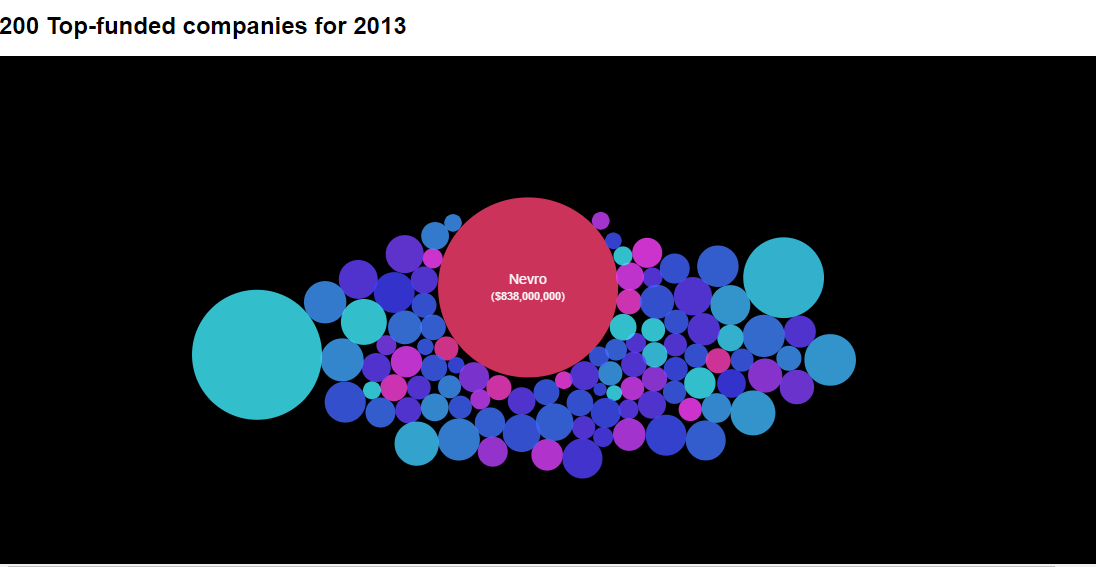
By the midterm, we had built a packed bubbles visualization (live version here). Bubbles were colored by category based on investment type, and their size was proportional to the amount invested. When the user hovered a mouse over the bubbles, they grew to a larger size and displayed the company name and total amount invested.
From there, we began adding information about the investors as well. I started out by drawing a ring of investors with the company bubbles clustered in the center of the circle (forgot to take a screenshot of that version), but there were so many investors that they overlapped and formed a solid ring. Instead, I ended up placing the investors on a spiral and scaling them according to the amount that they invested as well.

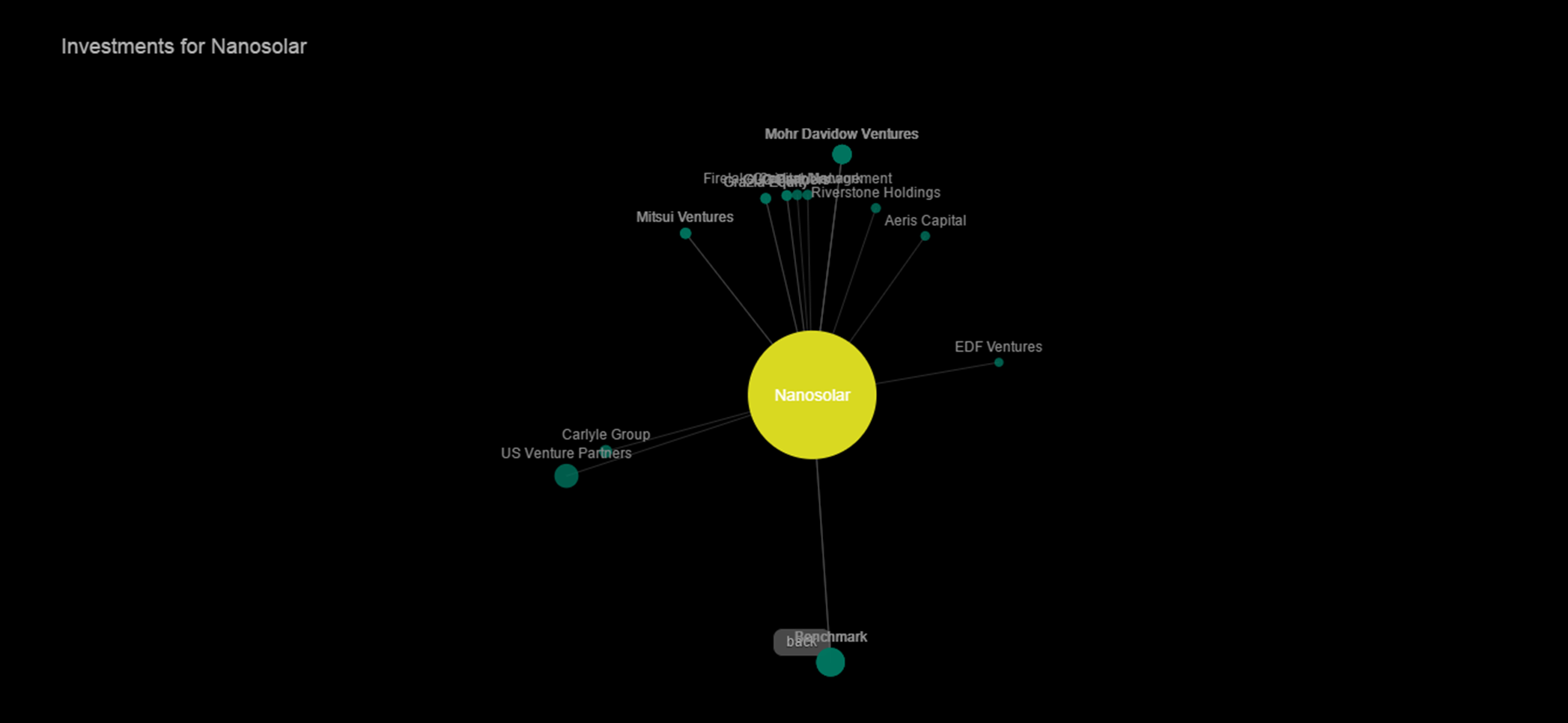
We were also asked to add a second view, accessed by clicking on a company, which showed the selected company at the center of the screen and the investors that had invested in that company around the outside of the ring. We included a back button with highlight on hover and other features as well.
For my personalized visualization, I wanted to focus on the connections between companies and investors. Rather than splitting the view into two separate screens, I wanted to show the connections in a single visualization when the user hovered the mouse over an investor or a company. This way, the user can look for patterns in how investors invest, the number of investors per company, or other potentially interesting features of the dataset, without having to move back and forth between two separate views by clicking.
Actually activating this behavior was something of a challenge. Just after the midterm, I completely rewrote my code to be based on Javascript prototypes rather than simple class functions. This wasn’t required for the class, but I was curious to know more about how prototypes worked, and it seemed like a good opportunity to experiment. Because all of the visualization behaviors in p5.js have to be written manually, I had to go back through and update the entire project to accommodate the new structure, in addition to reshaping my object definitions and data structure to optimize searching for the variables I was most interested in.
Data management
The question of how best to index the data was an ongoing concern, and something that changed with each new version of the code. Because this project was a gradual evolution rather than a pre-planned structure, we came up with needs that we hadn’t anticipated and needed to adjust the data pre-processing to match. I think I ended up re-configuring my basic data structure 3 or 4 times during the course of the semester in order to optimize sorting and storage of the information, and minimize processing power required for each step. (Of course, each of these changes also had implications for any function that used the data structure, so each restructuring step required editing all of the code.)
The data was imported from two separate .csv files, one containing information about each company and the amount invested in it, and the other containing information about the investors and how much they had invested. We then wrote filtering and sorting algorithms to find the top 200 companies and all of the investors connected to them, and to aggregate total amounts invested for each group. This information was stored in a company and an investor array, which was then used to generate the “particles” for display. To draw connections between the company and investor particles, I created a connections array that contained both a particle and an investor particle, as well as information about the investment amount for that particular connection. The basic visualization uses two separate arrays of company and investor objects to draw the basic bubble force diagram and spiral, and then there is a mouse highlight function that matches the selected investor and company to the appropriate connections in the list.
In order to draw connections between companies and investors on one screen, I ended up creating an update function within each object class that checks whether the object is selected and (if it is) looks up the list of connected entities. Getting full reciprocity without stomping on shared variables and crashing the program was a bit tricky, but I managed it eventually.
Final version
After updating the visual styling and tweaking other features, the current version looks like this: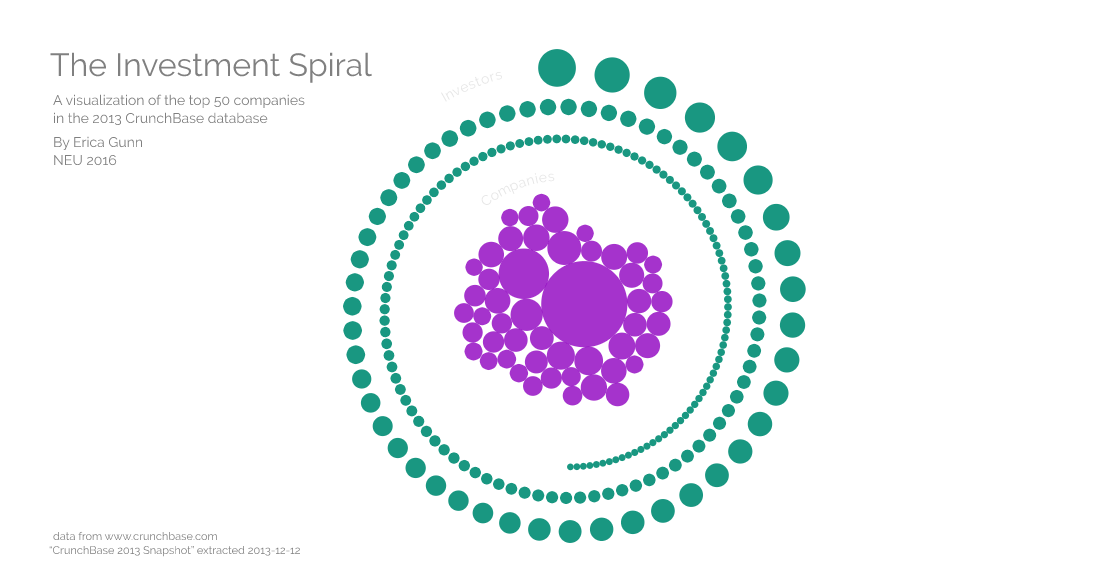
When a user highlights a company, it updates the display of the investors related to that company, and adds labels to identify them.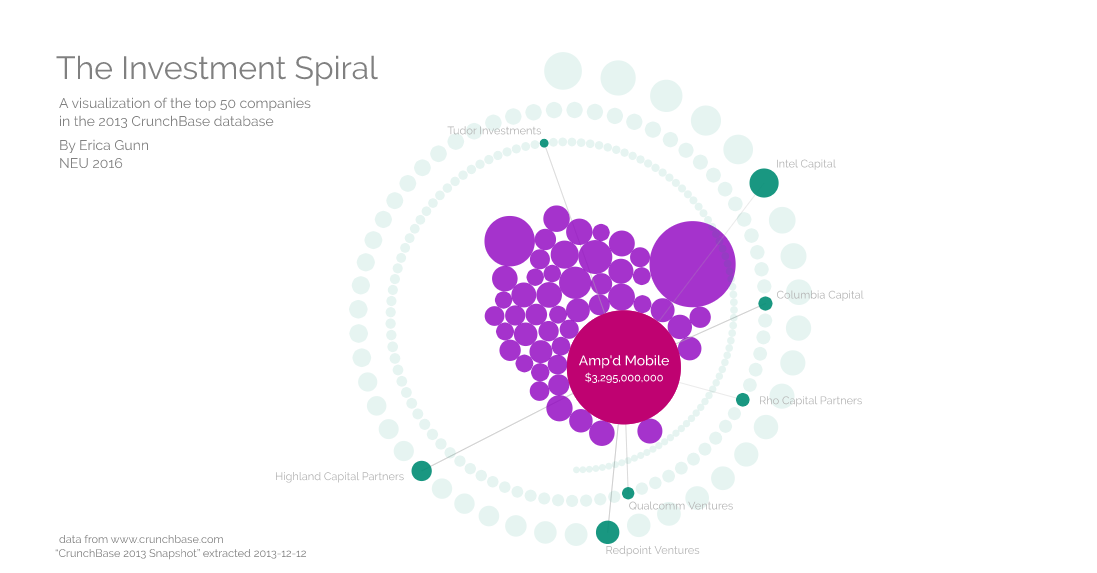
Similarly, highlighting an investor shows the companies connected to it.

I chose to change the company color on highlight because it’s hard to keep track of one particular company in the moving cluster. Because the investors have fixed positions and are organized by size, it’s easy to tell the difference between a highlighted and a non-highlighted investor, and I didn’t feel that it was necessary to change the color on highlight there. I also decided not to resize the target company and investor particles when drawing connections, because the size is important when comparing them to others in the dataset. It would be easier to add labels to the companies if I changed their size, though, so I may need to do that in a future version.
Future directions
I am still tweaking the small details of the visualization to make it more functional and user-friendly. I added a function to detect overlaps in the investor labels when a company is highlighted. If two labels overlap, it will move one up and one down until it is possible to read the text. In some cases, this causes the labels to move further from their investor particles than I would like, so I need to see if I can improve that. I’d also like to include optimization in the x-direction, so that the program will move a label left or right to avoid collisions, in addition to up and down. It may also be necessary to explicitly code a minimization step to “stick” the label to its parent particle; in a couple of instances, labels have a tendency to wander off during the optimization, making it harder to tell which particle they relate to.
It might also be helpful to include labels for the company particles when an investor is highlighted, and to indicate relative investment amounts for each connection shown. Adding that much extra text without crowding the visualization is something of a challenge. I considering adding a click functionality here, so that clicking on a company or investor adds extra details in the labeling, and clicking off of the company (or mousing over a different one) returns to the original behavior. That’s less disruptive than changing screens, but also allows the viewer another level of control over the amount of detail that they want to see.
I don’t expect to get all of these details cleaned up in time for our final presentations tomorrow, but those would be my primary areas of focus for a future version.
Reflections
In the end, I don’t think that this specific visualization was the most important outcome of the class. I could have made a similar visualization much more quickly in d3, but coding it from the bottom up in another library helped me to separate Javascript functionality from d3 functionality (since I learned them together, all of the concepts overlapped in my mind before, and I didn’t really know where d3 ended and Javascript began). It also helped to get “under the hood” a bit and understand what was going on in the background, for d3 and other libraries, and gave me an appreciation for all of the things that d3 does for you automatically (nodes and links arrays, anyone??). Seeing how these things worked from the fundamentals has improved my comfort and understanding of d3, even though I never used it here.
In addition to helping solidify my understanding from last semester, this class helped to increase my code fluency in general, and made me more confident in writing functionality on my own. It was helpful to write a force layout from scratch with custom labeling and mouse selection behavior, rather than relying on a library of pre-packaged functions. Knowing how to do that makes it easier to think outside of the box.
It was also helpful to see how much the data structure matters to the final code, and to be reminded of the need to consider the final use case when doing the initial data prep. We didn’t know what tools we’d be using or where we’d be going when we started (or really, almost until the end of the semester), and so I spent a lot of time going back and reworking to make things smarter after the fact. Having a clear plan for the things I needed to access in the data from the beginning would have made life a lot easier later on.
Experimenting with prototypes and comparing that to simple class functions was also helpful. I’m not sure that including prototypes increased the efficiency of my code in this case, because the company and investor particles had such different functionality in the end. Still, this project gave me a better understanding of when it is appropriate to use prototypes, and when it may not be necessary. (Pedro told me that I didn’t really need them here at the beginning of this little adventure, but we agreed that it would be a good exercise to try it anyway, and I think it was worth the additional effort to do so.)